Automated Intelligence Gateway
Betfred's infrastructure spans AWS cloud, on-premise retail shop systems, and hybrid workloads. Today, these are managed with separate tools, manual processes, and reactive monitoring. This initiative creates a unified intelligence gateway that proactively manages, monitors, and optimises the entire estate — predicting issues before they impact customers.
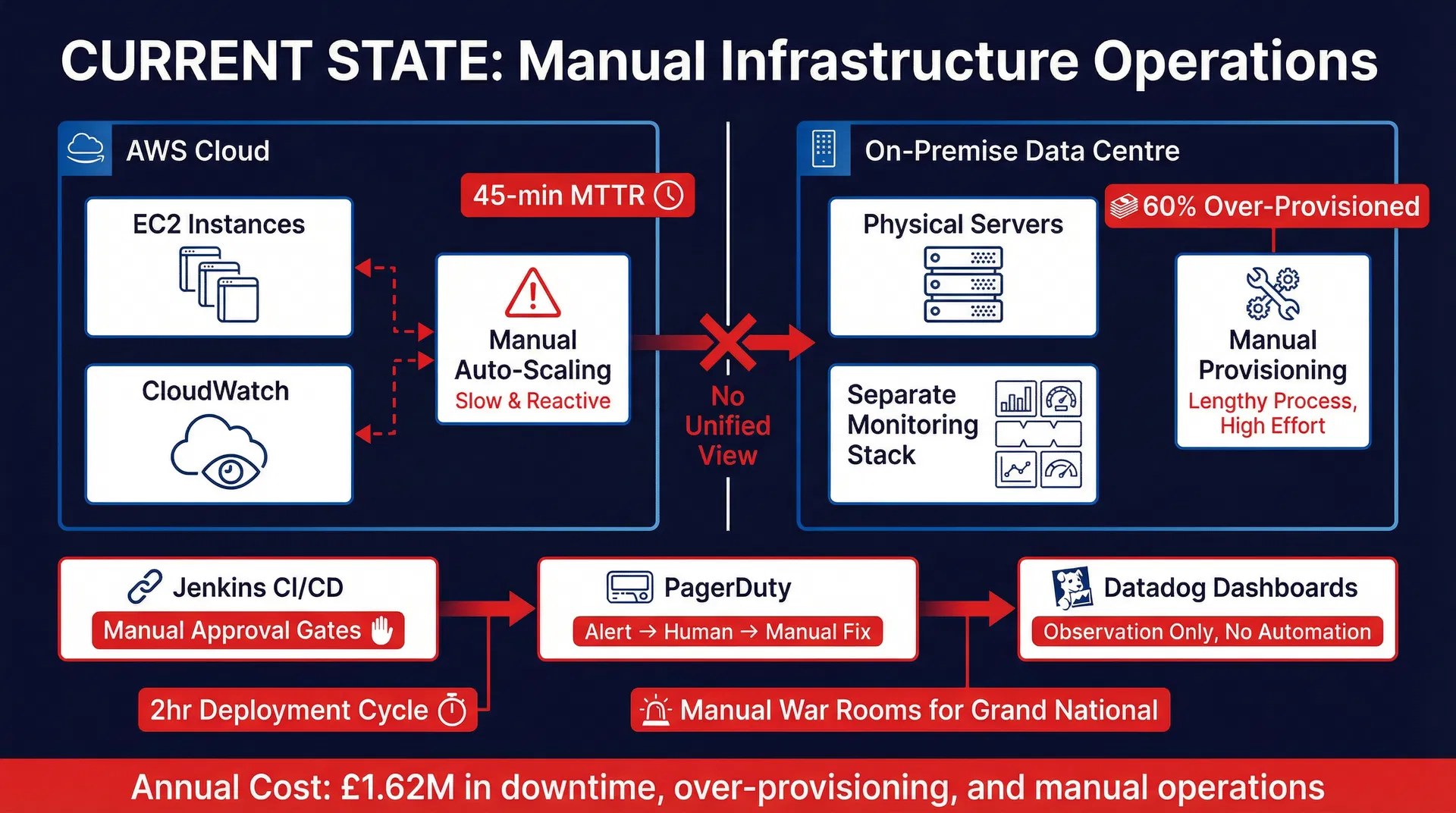
Where Betfred Stands Today: Manual, Reactive, Fragmented
Betfred's infrastructure operations rely on manual provisioning, reactive monitoring, and separate toolchains for cloud and on-premise environments. During peak events like the Grand National, the team scales manually based on experience rather than predictive analytics.
Infrastructure Transformation: Toggle to Compare
Interactive Architecture View
Total Cost of Ownership: Current vs. Intelligence Gateway
Annual Operational Cost Comparison
| Cost Category | Manual Ops (Current) | Intelligence Gateway (Future) | Annual Saving |
|---|---|---|---|
| Over-Provisioned Compute60% idle time → right-sized with predictive scaling | £280,000 | £70,000 | £210,000 |
| Downtime & Incident Cost45-min MTTR → 5-min MTTR with self-healing | £340,000 | £68,000 | £272,000 |
| Ops Team (Manual Tasks)Manual provisioning/monitoring → 80% automated | £520,000 | £260,000 | £260,000 |
| Multiple Monitoring ToolsCloudWatch + Datadog + custom → unified platform | £180,000 | £95,000 | £85,000 |
| Intelligence Gateway PlatformKubernetes + ArgoCD + Crossplane + ML pipeline | £0 | £320,000 | -£320,000 |
| Peak Event PreparationManual war rooms → automated predictive scaling | £120,000 | £30,000 | £90,000 |
| Compliance & AuditManual audit trails → continuous policy enforcement | £95,000 | £25,000 | £70,000 |
| Deployment FailuresManual rollbacks → automated canary with rollback | £85,000 | £15,000 | £70,000 |
| Total Annual Cost | £1,620,000 | £883,000 | £737,00045% reduction |
Net Annual Saving
After platform investment, Betfred saves £737K annually while gaining predictive capabilities, self-healing automation, and unified hybrid management.
Four Pillars of the Intelligence Gateway
The gateway is built on four interconnected pillars, each addressing a critical gap in Betfred's current operations.
Unified Control Plane
Single pane of glass for all infrastructureSeparate CloudWatch, Datadog, and on-premise monitoring tools with no cross-environment correlation.
Crossplane + Kubernetes providing a single API for managing AWS, on-premise, and edge resources. One dashboard, one policy engine, one source of truth.
Predictive Scaling Engine
Scale before demand arrivesReactive auto-scaling with fixed CPU thresholds. Manual pre-provisioning for Grand National based on previous year's estimates.
ML models trained on 3 years of Betfred event data (Grand National, Cheltenham, Premier League) predicting load 2 hours ahead. KEDA scales pods based on predictions, not reactions.
Self-Healing Automation
Fix issues before humans noticePagerDuty alert → on-call engineer wakes up → investigates → manually remediates. Average 45-minute MTTR.
Automated runbooks triggered by anomaly detection. 80% of incidents resolved without human intervention. Escalation only for novel or critical scenarios.
Intelligent Deployment
Zero-downtime progressive rolloutsJenkins pipelines with manual approval gates. Full rollouts with manual rollback if issues detected. Average 2-hour deployment cycle.
GitOps-driven canary deployments with automated observability gates. Traffic progressively shifts from 5% → 100% with automatic rollback if error rate exceeds threshold.
Automated Remediation Runbooks
Each runbook defines a trigger condition, automated action, and escalation path. These replace the current manual investigation and remediation workflow.
Progressive Delivery Pipeline
From code commit to production in under 35 minutes with automated quality gates, canary analysis, and instant rollback.
Grand National: Predictive Scaling in Action
The Grand National generates 10x normal traffic in a 15-minute window. Today, Betfred manually pre-provisions based on last year's numbers. The Intelligence Gateway uses ML to predict and pre-scale automatically.
Current Approach (Manual)
Future Approach (Predictive)
Future Solution: What Betfred Will See
End-State Vision

Intelligence Gateway Dashboard
Unified control plane showing all infrastructure across AWS, on-premise, and edge. Real-time health status, resource utilisation, cost tracking, and anomaly alerts in a single view.